🤖 Почему модели лучше отвечают на вопросы по тексту, чем по изображениям — и как это исправить?
Vision-Language модели (VLMs) сильно хуже справляются с вопросами про картинки (*«Сколько книг на изображении?»*), чем с теми же вопросами по тексту (*«Сколько книг в описании?»*). И нашли способ улучшить результат на +4.6%, закрыв треть разрыва между модальностями! Вот что они сделали 👇
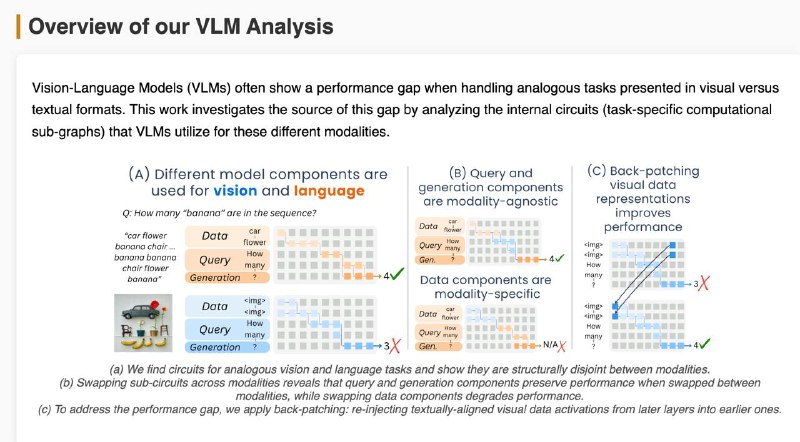
🔬 Они разделили вход на три части: • Данные (изображение или текст), • Вопрос (*how many…*), • Ответ (предсказание последнего слова).
🧠 Что нашли:
1️⃣Мозги у модели разные для текста и картинок — цепочки внимания и нейроны почти не совпадают (всего ~18%). Особенно в частях, где обрабатываются данные и вопрос.
2️⃣Часть, отвечающая за генерацию ответа, похожа — можно даже подменить её между модальностями, и модель почти не теряет в точности.
3️⃣Часть, которая "смотрит" на данные — строго модальная. Визуальный поток информации идёт по другому пути, и замена разрушает результат.
4️⃣Проблема в том, что изображение “становится понятным” слишком поздно. В поздних слоях визуальные данные уже похожи на текстовые — но модель не успевает этим воспользоваться.
💡 Решение: "перемотать" визуальные данные из поздних слоёв обратно в ранние (back-patching) — это помогает модели раньше "понять" картинку.
📈 Результат: +4.6% точности при ответах на вопросы по изображению — и треть разрыва с текстом закрыта!
🧩 Вывод: архитектура не виновата. Просто визуальные данные нужно правильно "подать" — и VLM начинает думать почти как человек.
🤖 Почему модели лучше отвечают на вопросы по тексту, чем по изображениям — и как это исправить?
Vision-Language модели (VLMs) сильно хуже справляются с вопросами про картинки (*«Сколько книг на изображении?»*), чем с теми же вопросами по тексту (*«Сколько книг в описании?»*). И нашли способ улучшить результат на +4.6%, закрыв треть разрыва между модальностями! Вот что они сделали 👇
🔬 Они разделили вход на три части: • Данные (изображение или текст), • Вопрос (*how many…*), • Ответ (предсказание последнего слова).
🧠 Что нашли:
1️⃣Мозги у модели разные для текста и картинок — цепочки внимания и нейроны почти не совпадают (всего ~18%). Особенно в частях, где обрабатываются данные и вопрос.
2️⃣Часть, отвечающая за генерацию ответа, похожа — можно даже подменить её между модальностями, и модель почти не теряет в точности.
3️⃣Часть, которая "смотрит" на данные — строго модальная. Визуальный поток информации идёт по другому пути, и замена разрушает результат.
4️⃣Проблема в том, что изображение “становится понятным” слишком поздно. В поздних слоях визуальные данные уже похожи на текстовые — но модель не успевает этим воспользоваться.
💡 Решение: "перемотать" визуальные данные из поздних слоёв обратно в ранние (back-patching) — это помогает модели раньше "понять" картинку.
📈 Результат: +4.6% точности при ответах на вопросы по изображению — и треть разрыва с текстом закрыта!
🧩 Вывод: архитектура не виновата. Просто визуальные данные нужно правильно "подать" — и VLM начинает думать почти как человек.
The company maintains that it cannot act against individual or group chats, which are “private amongst their participants,” but it will respond to requests in relation to sticker sets, channels and bots which are publicly available. During the invasion of Ukraine, Pavel Durov has wrestled with this issue a lot more prominently than he has before. Channels like Donbass Insider and Bellum Acta, as reported by Foreign Policy, started pumping out pro-Russian propaganda as the invasion began. So much so that the Ukrainian National Security and Defense Council issued a statement labeling which accounts are Russian-backed. Ukrainian officials, in potential violation of the Geneva Convention, have shared imagery of dead and captured Russian soldiers on the platform. In the past, it was noticed that through bulk SMSes, investors were induced to invest in or purchase the stocks of certain listed companies. Stocks dropped on Friday afternoon, as gains made earlier in the day on hopes for diplomatic progress between Russia and Ukraine turned to losses. Technology stocks were hit particularly hard by higher bond yields. Pavel Durov, a billionaire who embraces an all-black wardrobe and is often compared to the character Neo from "the Matrix," funds Telegram through his personal wealth and debt financing. And despite being one of the world's most popular tech companies, Telegram reportedly has only about 30 employees who defer to Durov for most major decisions about the platform. Telegram does offer end-to-end encrypted communications through Secret Chats, but this is not the default setting. Standard conversations use the MTProto method, enabling server-client encryption but with them stored on the server for ease-of-access. This makes using Telegram across multiple devices simple, but also means that the regular Telegram chats you’re having with folks are not as secure as you may believe.
from ua