group-telegram.com/kitty_bytes/14
Last Update:
Large Parallelism Post: Part I
#parallelism
Я долго ничего не публиковал, потому что решил сделать большой пост о параллелизме в нейросетях. Как оказалось, эта тема довольно обширная и с регулярными публикациями. Пришлось потратить много времени на сбор информации, структуризацию и написание текста. В конечном итоге материала оказалось так много, что я решил разбить его на серию постов.
В первой части собраны базовые методы параллелизма:
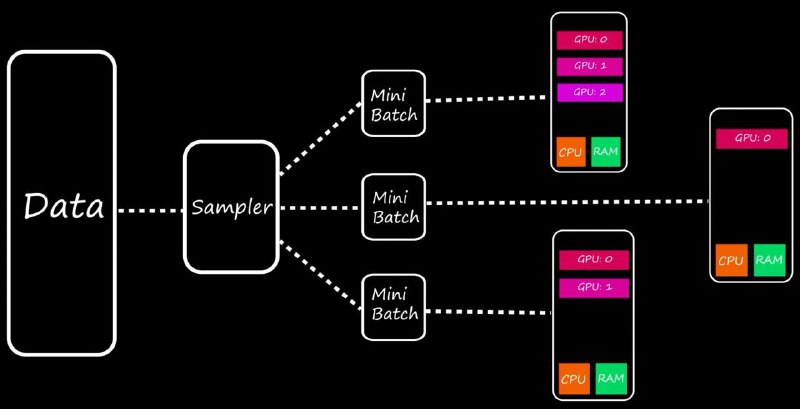
Data Parallel - самый простой метод параллелизма, в котором мы копируем модель на все GPU, и обучаем каждую ее копию, после чего аккумулируем градиенты
Distributed Data Parallel - обновление метода Data Parallel с возможностью параллелизма модели на нескольких нодах
Model Parallelism - если у нас большая модель, то давайте просто порежем ее слои
Pipeline Parallelism - улучшение Model Parallelism, который разработали ребята из Google, позволяющий избегать простоя GPU с помощью разделения данных на micro-batches
Читать больше в Teletype
Если чтиво вам покажется довольно простым, то советую дождаться разбора методов Tensor Parallelism и ZeRO