group-telegram.com/rndcv_team/133
Last Update:
SVGDreamer: Text Guided SVG Generation with Diffusion Model
⚡️ В этом году на CVPR была представлена статья SVGDreamer, посвященная text-to-svg генерации. Предложенная модель обладает более высоким визуальным качеством и разнородностью генерации, а благодаря разделению на семантические слои сгенерированные изображения легко редактировать.
Что внутри:
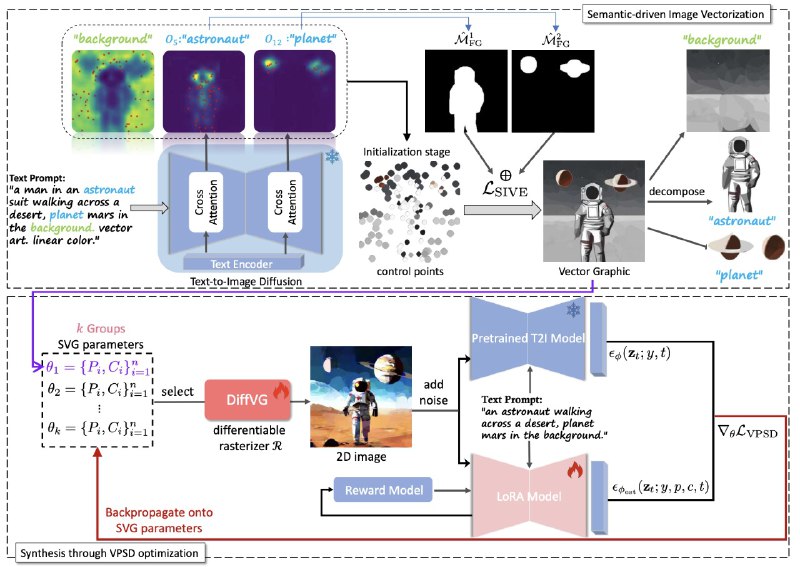
💠 Semantic-driven Image Vectorization (SIVE) разделяет семантические слои на изображении, что позволяет отдельно векторизовать объекты и фон картинки. Такое разделение необходимо, чтобы передний план и фон не были связаны друг с другом, и каждый объект на картинке мог легко редактироваться независимо от остальных. Контрольные точки кривых, задающих объекты в векторной графике, инициализируются на основе cross-attention map, после чего оптимизируются с помощью SIVE-лосса.
💠 Vectorized Particle-based Score Distillation (VPSD) для синтеза изображения. Авторы моделируют SVG-изображение распределением контрольных точек и их цветовых значений. Растеризованная с помощью дифференцируемого растеризатора diffvg картинка вместе с текстовым промптом подается на вход в предобученную text-to-image диффузионную модель и дообучаемую LoRA.
💠 Также авторы используют предобученную reward-модель, выставляющую скоры сэмплам из LoRA, и дополнительно считают reward-лосс.
🖼️ Для генерации доступны различные стили изображения, такие как скетч, пиксель-арт и рисунок. По метрикам модель обходит существующие решения, такие как DiffSketcher и VectorFusion.
🎉 В открытый доступ выложен код SVGDreamer, который (мы проверили) запускается из коробки.
📜 ArXiv