Telegram Group »
United States »
📈 ТехноТренды: Технологии, Тренды, IT »
Telegram Webview »
Post 250

Продолжаем изучать стэнфордский отчет AI Index Report 2025 (начало тут и тут). Вторая глава «Technical Performance» посвящена эволюции технических возможностей ИИ-систем.
🔥 Контекст и ключевые тренды. В 2024 году модели сильно продвинулись в классических тестах, но при этом столкнулись с фундаментальными ограничениями в сложных задачах.
1️⃣ Прорывы в бенчмарках и специализированных задачах
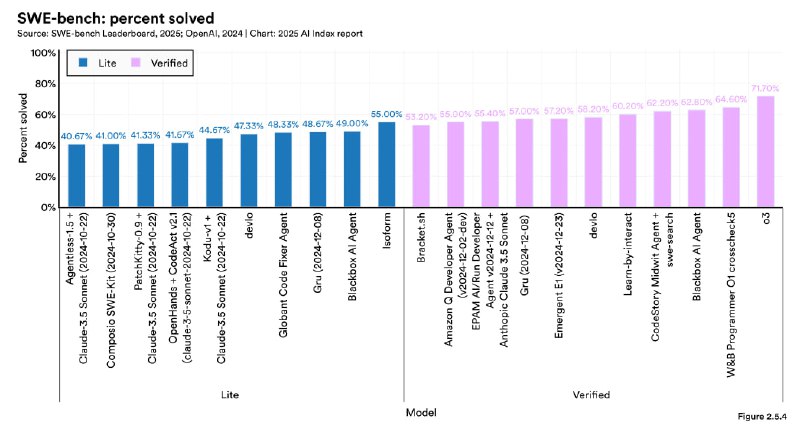
▫️ Рекорды на новых тестах. В сложных комплексных бенчмарках (MMMU, GPQA, SWE-bench) ИИ за год показал впечатляющий прогресс. Например, на SWE-bench в 2023 году модели решали лишь 4.4% задач, а в 2024 — 71.7%. Кстати, и мы на канале фиксировали этот тренд.
▫️Преодоление «человеческого» барьера. Благодаря улучшению алгоритмов рассуждений и интеграции символьных методов модели вроде o1-preview и Claude 3.5 Sonnet достигли 97,9% точности на датасете MATH — выше человеческого уровня (90%).
2️⃣ Конвергенция технологий и сокращение разрывов
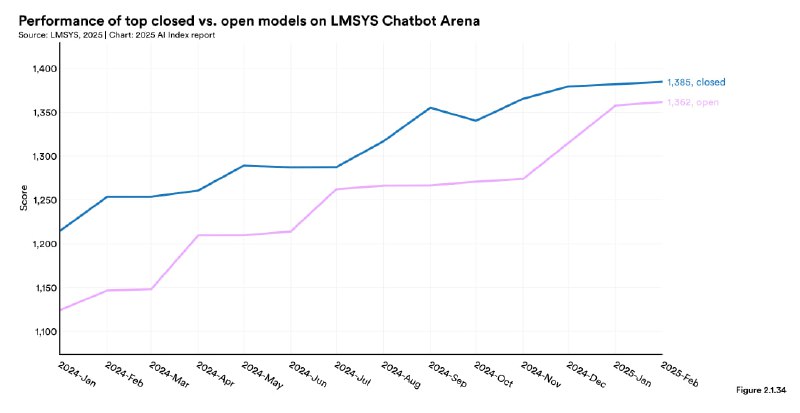
▫️Открытые vs. закрытые модели. Разрыв в производительности между топовыми открытыми и проприетарными моделями сократился с 8% до 1.7% (уровень статистической погрешности), что демократизирует доступ к передовым ИИ-технологиям.
👉 Добавим от себя пару комментариев:
• опенсорс заставляет даже завзятых проприетарщиков, таких как OpenAI, выпускать бесплатные версии своих моделей;
• но демократизация доступа к ИИ имеет обратную сторону — проблему безопасности данных.
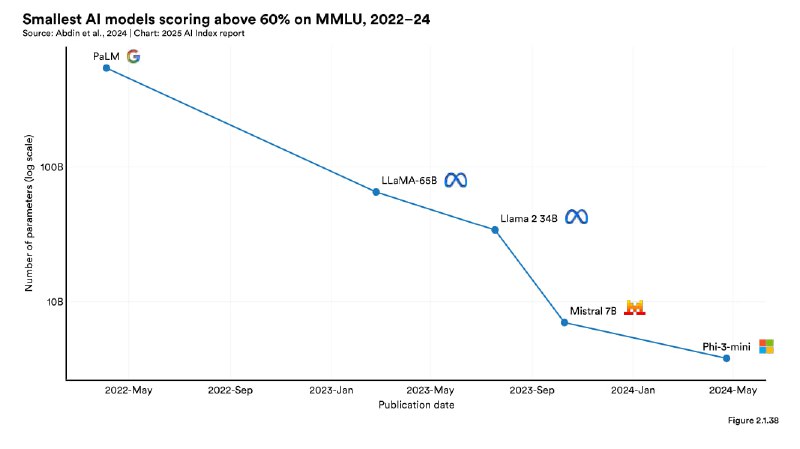
▫️Малые модели vs. большие. Успехи таких проектов, как Mistral и Phi-3, доказали, что могут небольшие модели при правильном обучении. Phi-3-mini (3.8B параметров) сравнялась по эффективности с PaLM (540B) — 142-кратное сокращение размера при той же производительности. Качество работы модели больше не зависит линейно от масштаба, и мы об этом писали.
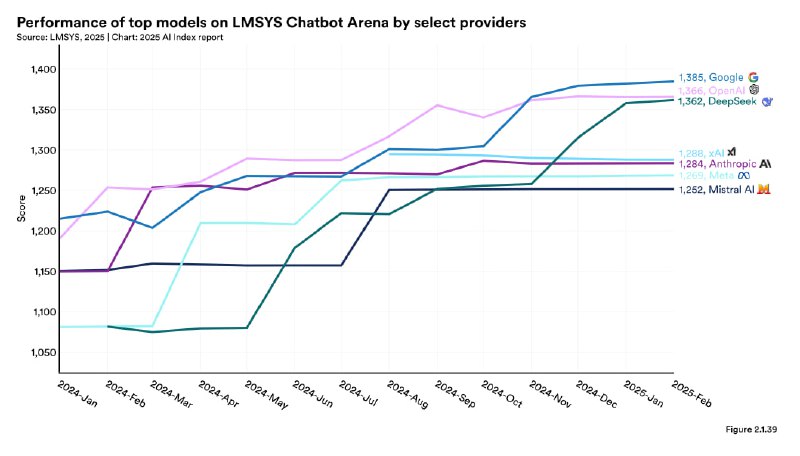
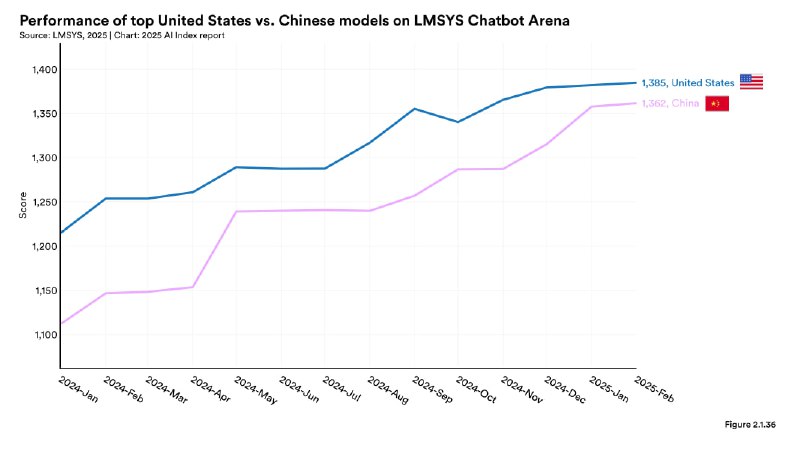
▫️Глобальное выравнивание. Китайские модели (напр., DeepSeek и Qwen) догнали по качеству американские. Разрыв на бенчмарках за год сократился с десятков до долей процента.
3️⃣ Новые парадигмы обучения
Индустрия освоила test-time compute (TTC) — метод оптимизации работы ИИ, при котором ресурсы выделяются динамически, а не фиксируются заранее. Это позволяет модели дольше «размышлять» над сложными задачами, улучшая качество ответов.
▫️Например, модель o1 от OpenAI решает 74.4% задач математической олимпиады против 9.3% у GPT-4o. Но требует в 6 раз больше вычислительной мощности и работает в 30 раз медленнее.
4️⃣ Революция в генерации видео
Видеогенерация в продвинутых моделях SORA и Veo 2 преодолела проблему контекстной согласованности — теперь возможно создание минутных роликов с физически точной динамикой и детализацией, которые были немыслимы еще год назад.
5️⃣ Ограничения и «стены» прогресса
Несмотря на успехи в математике, модели проваливаются в задачах, требующих многошаговой логики. Лучшие системы решают лишь 2% задач из FrontierMath и 8-12% на PlanBench и Humanity’s Last Exam, что указывает на фундаментальные ограничения текущих архитектур.
🎯 Выводы
👉 Главный тренд: ИИ становится быстрее и доступнее, но упирается в непреодолимые барьеры в сложных рассуждениях. Дальнейшее улучшение работы потребует смены парадигмы, а не оптимизации существующих подходов, резюмируют авторы.
👉 Перспективы: Активное развитие агентного ИИ (что совпадает и с нашей оценкой) и поиск альтернатив масштабированию (нейроморфные чипы, квантовые методы). ИИ-агенты уже используются для автоматизации программирования, анализа данных и управления ИТ-инфраструктурой. Отдельно подчеркивается их роль в науке и робототехнике.
👉 Продолжение следует...
#AI #ниокр #bigdata #инференс #тренды #аналитика #тесты #AI_index_report_2025
🚀 ©ТехноТренды
🔥 Контекст и ключевые тренды. В 2024 году модели сильно продвинулись в классических тестах, но при этом столкнулись с фундаментальными ограничениями в сложных задачах.
1️⃣ Прорывы в бенчмарках и специализированных задачах
▫️ Рекорды на новых тестах. В сложных комплексных бенчмарках (MMMU, GPQA, SWE-bench) ИИ за год показал впечатляющий прогресс. Например, на SWE-bench в 2023 году модели решали лишь 4.4% задач, а в 2024 — 71.7%. Кстати, и мы на канале фиксировали этот тренд.
▫️Преодоление «человеческого» барьера. Благодаря улучшению алгоритмов рассуждений и интеграции символьных методов модели вроде o1-preview и Claude 3.5 Sonnet достигли 97,9% точности на датасете MATH — выше человеческого уровня (90%).
2️⃣ Конвергенция технологий и сокращение разрывов
▫️Открытые vs. закрытые модели. Разрыв в производительности между топовыми открытыми и проприетарными моделями сократился с 8% до 1.7% (уровень статистической погрешности), что демократизирует доступ к передовым ИИ-технологиям.
👉 Добавим от себя пару комментариев:
• опенсорс заставляет даже завзятых проприетарщиков, таких как OpenAI, выпускать бесплатные версии своих моделей;
• но демократизация доступа к ИИ имеет обратную сторону — проблему безопасности данных.
▫️Малые модели vs. большие. Успехи таких проектов, как Mistral и Phi-3, доказали, что могут небольшие модели при правильном обучении. Phi-3-mini (3.8B параметров) сравнялась по эффективности с PaLM (540B) — 142-кратное сокращение размера при той же производительности. Качество работы модели больше не зависит линейно от масштаба, и мы об этом писали.
▫️Глобальное выравнивание. Китайские модели (напр., DeepSeek и Qwen) догнали по качеству американские. Разрыв на бенчмарках за год сократился с десятков до долей процента.
3️⃣ Новые парадигмы обучения
Индустрия освоила test-time compute (TTC) — метод оптимизации работы ИИ, при котором ресурсы выделяются динамически, а не фиксируются заранее. Это позволяет модели дольше «размышлять» над сложными задачами, улучшая качество ответов.
▫️Например, модель o1 от OpenAI решает 74.4% задач математической олимпиады против 9.3% у GPT-4o. Но требует в 6 раз больше вычислительной мощности и работает в 30 раз медленнее.
4️⃣ Революция в генерации видео
Видеогенерация в продвинутых моделях SORA и Veo 2 преодолела проблему контекстной согласованности — теперь возможно создание минутных роликов с физически точной динамикой и детализацией, которые были немыслимы еще год назад.
5️⃣ Ограничения и «стены» прогресса
Несмотря на успехи в математике, модели проваливаются в задачах, требующих многошаговой логики. Лучшие системы решают лишь 2% задач из FrontierMath и 8-12% на PlanBench и Humanity’s Last Exam, что указывает на фундаментальные ограничения текущих архитектур.
🎯 Выводы
👉 Главный тренд: ИИ становится быстрее и доступнее, но упирается в непреодолимые барьеры в сложных рассуждениях. Дальнейшее улучшение работы потребует смены парадигмы, а не оптимизации существующих подходов, резюмируют авторы.
👉 Перспективы: Активное развитие агентного ИИ (что совпадает и с нашей оценкой) и поиск альтернатив масштабированию (нейроморфные чипы, квантовые методы). ИИ-агенты уже используются для автоматизации программирования, анализа данных и управления ИТ-инфраструктурой. Отдельно подчеркивается их роль в науке и робототехнике.
👉 Продолжение следует...
#AI #ниокр #bigdata #инференс #тренды #аналитика #тесты #AI_index_report_2025
🚀 ©ТехноТренды
group-telegram.com/technologies_trends/250
Create:
Last Update:
Last Update:
Продолжаем изучать стэнфордский отчет AI Index Report 2025 (начало тут и тут). Вторая глава «Technical Performance» посвящена эволюции технических возможностей ИИ-систем.
🔥 Контекст и ключевые тренды. В 2024 году модели сильно продвинулись в классических тестах, но при этом столкнулись с фундаментальными ограничениями в сложных задачах.
1️⃣ Прорывы в бенчмарках и специализированных задачах
▫️ Рекорды на новых тестах. В сложных комплексных бенчмарках (MMMU, GPQA, SWE-bench) ИИ за год показал впечатляющий прогресс. Например, на SWE-bench в 2023 году модели решали лишь 4.4% задач, а в 2024 — 71.7%. Кстати, и мы на канале фиксировали этот тренд.
▫️Преодоление «человеческого» барьера. Благодаря улучшению алгоритмов рассуждений и интеграции символьных методов модели вроде o1-preview и Claude 3.5 Sonnet достигли 97,9% точности на датасете MATH — выше человеческого уровня (90%).
2️⃣ Конвергенция технологий и сокращение разрывов
▫️Открытые vs. закрытые модели. Разрыв в производительности между топовыми открытыми и проприетарными моделями сократился с 8% до 1.7% (уровень статистической погрешности), что демократизирует доступ к передовым ИИ-технологиям.
👉 Добавим от себя пару комментариев:
• опенсорс заставляет даже завзятых проприетарщиков, таких как OpenAI, выпускать бесплатные версии своих моделей;
• но демократизация доступа к ИИ имеет обратную сторону — проблему безопасности данных.
▫️Малые модели vs. большие. Успехи таких проектов, как Mistral и Phi-3, доказали, что могут небольшие модели при правильном обучении. Phi-3-mini (3.8B параметров) сравнялась по эффективности с PaLM (540B) — 142-кратное сокращение размера при той же производительности. Качество работы модели больше не зависит линейно от масштаба, и мы об этом писали.
▫️Глобальное выравнивание. Китайские модели (напр., DeepSeek и Qwen) догнали по качеству американские. Разрыв на бенчмарках за год сократился с десятков до долей процента.
3️⃣ Новые парадигмы обучения
Индустрия освоила test-time compute (TTC) — метод оптимизации работы ИИ, при котором ресурсы выделяются динамически, а не фиксируются заранее. Это позволяет модели дольше «размышлять» над сложными задачами, улучшая качество ответов.
▫️Например, модель o1 от OpenAI решает 74.4% задач математической олимпиады против 9.3% у GPT-4o. Но требует в 6 раз больше вычислительной мощности и работает в 30 раз медленнее.
4️⃣ Революция в генерации видео
Видеогенерация в продвинутых моделях SORA и Veo 2 преодолела проблему контекстной согласованности — теперь возможно создание минутных роликов с физически точной динамикой и детализацией, которые были немыслимы еще год назад.
5️⃣ Ограничения и «стены» прогресса
Несмотря на успехи в математике, модели проваливаются в задачах, требующих многошаговой логики. Лучшие системы решают лишь 2% задач из FrontierMath и 8-12% на PlanBench и Humanity’s Last Exam, что указывает на фундаментальные ограничения текущих архитектур.
🎯 Выводы
👉 Главный тренд: ИИ становится быстрее и доступнее, но упирается в непреодолимые барьеры в сложных рассуждениях. Дальнейшее улучшение работы потребует смены парадигмы, а не оптимизации существующих подходов, резюмируют авторы.
👉 Перспективы: Активное развитие агентного ИИ (что совпадает и с нашей оценкой) и поиск альтернатив масштабированию (нейроморфные чипы, квантовые методы). ИИ-агенты уже используются для автоматизации программирования, анализа данных и управления ИТ-инфраструктурой. Отдельно подчеркивается их роль в науке и робототехнике.
👉 Продолжение следует...
#AI #ниокр #bigdata #инференс #тренды #аналитика #тесты #AI_index_report_2025
🚀 ©ТехноТренды
🔥 Контекст и ключевые тренды. В 2024 году модели сильно продвинулись в классических тестах, но при этом столкнулись с фундаментальными ограничениями в сложных задачах.
1️⃣ Прорывы в бенчмарках и специализированных задачах
▫️ Рекорды на новых тестах. В сложных комплексных бенчмарках (MMMU, GPQA, SWE-bench) ИИ за год показал впечатляющий прогресс. Например, на SWE-bench в 2023 году модели решали лишь 4.4% задач, а в 2024 — 71.7%. Кстати, и мы на канале фиксировали этот тренд.
▫️Преодоление «человеческого» барьера. Благодаря улучшению алгоритмов рассуждений и интеграции символьных методов модели вроде o1-preview и Claude 3.5 Sonnet достигли 97,9% точности на датасете MATH — выше человеческого уровня (90%).
2️⃣ Конвергенция технологий и сокращение разрывов
▫️Открытые vs. закрытые модели. Разрыв в производительности между топовыми открытыми и проприетарными моделями сократился с 8% до 1.7% (уровень статистической погрешности), что демократизирует доступ к передовым ИИ-технологиям.
👉 Добавим от себя пару комментариев:
• опенсорс заставляет даже завзятых проприетарщиков, таких как OpenAI, выпускать бесплатные версии своих моделей;
• но демократизация доступа к ИИ имеет обратную сторону — проблему безопасности данных.
▫️Малые модели vs. большие. Успехи таких проектов, как Mistral и Phi-3, доказали, что могут небольшие модели при правильном обучении. Phi-3-mini (3.8B параметров) сравнялась по эффективности с PaLM (540B) — 142-кратное сокращение размера при той же производительности. Качество работы модели больше не зависит линейно от масштаба, и мы об этом писали.
▫️Глобальное выравнивание. Китайские модели (напр., DeepSeek и Qwen) догнали по качеству американские. Разрыв на бенчмарках за год сократился с десятков до долей процента.
3️⃣ Новые парадигмы обучения
Индустрия освоила test-time compute (TTC) — метод оптимизации работы ИИ, при котором ресурсы выделяются динамически, а не фиксируются заранее. Это позволяет модели дольше «размышлять» над сложными задачами, улучшая качество ответов.
▫️Например, модель o1 от OpenAI решает 74.4% задач математической олимпиады против 9.3% у GPT-4o. Но требует в 6 раз больше вычислительной мощности и работает в 30 раз медленнее.
4️⃣ Революция в генерации видео
Видеогенерация в продвинутых моделях SORA и Veo 2 преодолела проблему контекстной согласованности — теперь возможно создание минутных роликов с физически точной динамикой и детализацией, которые были немыслимы еще год назад.
5️⃣ Ограничения и «стены» прогресса
Несмотря на успехи в математике, модели проваливаются в задачах, требующих многошаговой логики. Лучшие системы решают лишь 2% задач из FrontierMath и 8-12% на PlanBench и Humanity’s Last Exam, что указывает на фундаментальные ограничения текущих архитектур.
🎯 Выводы
👉 Главный тренд: ИИ становится быстрее и доступнее, но упирается в непреодолимые барьеры в сложных рассуждениях. Дальнейшее улучшение работы потребует смены парадигмы, а не оптимизации существующих подходов, резюмируют авторы.
👉 Перспективы: Активное развитие агентного ИИ (что совпадает и с нашей оценкой) и поиск альтернатив масштабированию (нейроморфные чипы, квантовые методы). ИИ-агенты уже используются для автоматизации программирования, анализа данных и управления ИТ-инфраструктурой. Отдельно подчеркивается их роль в науке и робототехнике.
👉 Продолжение следует...
#AI #ниокр #bigdata #инференс #тренды #аналитика #тесты #AI_index_report_2025
🚀 ©ТехноТренды
BY 📈 ТехноТренды: Технологии, Тренды, IT
Share with your friend now:
group-telegram.com/technologies_trends/250