
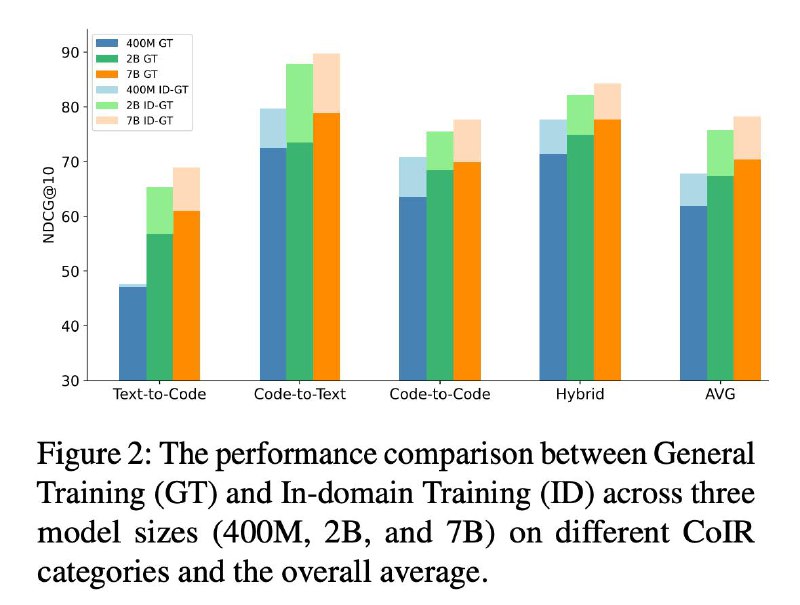
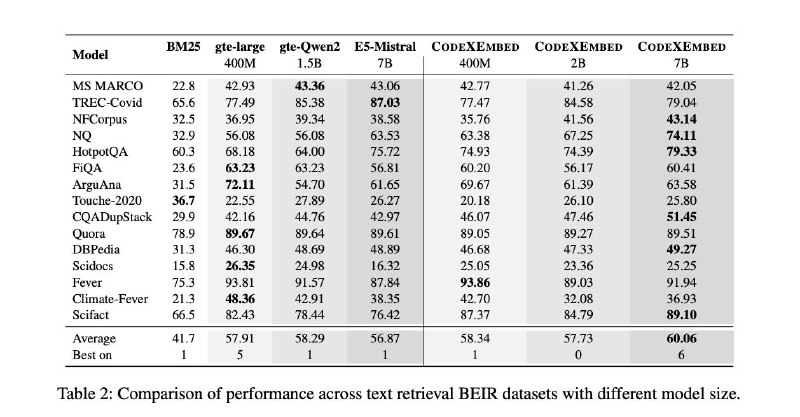
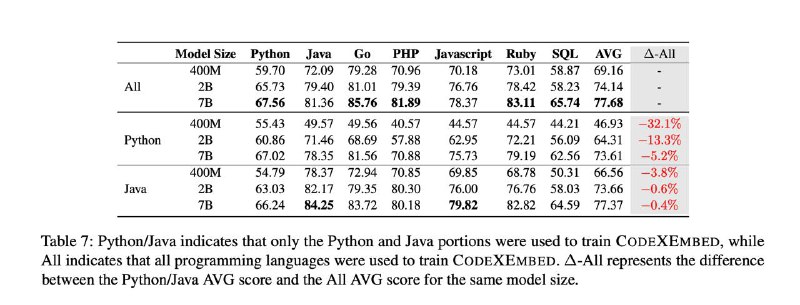
🚀Только что выпущено новое семейство моделей генерации кода Salesforce (SFR-Embedding-Code), занявшее 1-е место на бенчмарке CoIR!
Модель доступна в в 2-х размерах: 2B, 400M.
Основные характеристики:
1️⃣ Модель 2B: Занимает первое место в CoIR.
2️⃣ Модель 400M: демонстрирует лучшие показатели среди моделей на 0,5B параметров.
3️⃣ Поддерживает 12 языков программирования,
Пример Запуска:
✅Документация
✅Модель 400M
✅ Модель 2B
📌Лицензирование моделей: CC-BY-NC-SA-4.0 License.
@ai_machinelearning_big_data
#CodeAI #MLResearch #SOTA #OpenScience #code #llm #ml
Модель доступна в в 2-х размерах: 2B, 400M.
Основные характеристики:
1️⃣ Модель 2B: Занимает первое место в CoIR.
2️⃣ Модель 400M: демонстрирует лучшие показатели среди моделей на 0,5B параметров.
3️⃣ Поддерживает 12 языков программирования,
Python, Java, C++, JavaScript, C# и другие!Пример Запуска:
import torch.nn.functional as F
from transformers import AutoTokenizer, AutoModel
# Each query needs to be accompanied by an corresponding instruction describing the task.
query_instruction_example = "Given Code or Text, retrieval relevant content"
queries = [
"how to implement quick sort in Python?"
]
# No instruction needed for retrieval passages
passages = [
"def quick_sort(arr):\n if len(arr) <= 1:\n return arr\n pivot = arr[len(arr) // 2]\n left = [x for x in arr if x < pivot]\n middle = [x for x in arr if x == pivot]\n right = [x for x in arr if x > pivot]\n return quick_sort(left) + middle + quick_sort(right)",
"def bubble_sort(arr):\n n = len(arr)\n for i in range(n):\n for j in range(0, n-i-1):\n if arr[j] > arr[j+1]:\n arr[j], arr[j+1] = arr[j+1], arr[j]\n return arr"
]
# load model with tokenizer
model = AutoModel.from_pretrained('Salesforce/SFR-Embedding-Code-2B_R', trust_remote_code=True)
# get the embeddings
max_length = 32768
query_embeddings = model.encode_queries(queries, instruction=query_instruction_example, max_length=max_length)
passage_embeddings = model.encode_corpus(passages, max_length=max_length)
# normalize embeddings
query_embeddings = F.normalize(query_embeddings, p=2, dim=1)
passage_embeddings = F.normalize(passage_embeddings, p=2, dim=1)
scores = (query_embeddings @ passage_embeddings.T) * 100
print(scores.tolist())
✅Документация
✅Модель 400M
✅ Модель 2B
📌Лицензирование моделей: CC-BY-NC-SA-4.0 License.
@ai_machinelearning_big_data
#CodeAI #MLResearch #SOTA #OpenScience #code #llm #ml
group-telegram.com/ai_machinelearning_big_data/6575
Create:
Last Update:
Last Update:
🚀Только что выпущено новое семейство моделей генерации кода Salesforce (SFR-Embedding-Code), занявшее 1-е место на бенчмарке CoIR!
Модель доступна в в 2-х размерах: 2B, 400M.
Основные характеристики:
1️⃣ Модель 2B: Занимает первое место в CoIR.
2️⃣ Модель 400M: демонстрирует лучшие показатели среди моделей на 0,5B параметров.
3️⃣ Поддерживает 12 языков программирования,
Пример Запуска:
✅Документация
✅Модель 400M
✅ Модель 2B
📌Лицензирование моделей: CC-BY-NC-SA-4.0 License.
@ai_machinelearning_big_data
#CodeAI #MLResearch #SOTA #OpenScience #code #llm #ml
Модель доступна в в 2-х размерах: 2B, 400M.
Основные характеристики:
1️⃣ Модель 2B: Занимает первое место в CoIR.
2️⃣ Модель 400M: демонстрирует лучшие показатели среди моделей на 0,5B параметров.
3️⃣ Поддерживает 12 языков программирования,
Python, Java, C++, JavaScript, C# и другие!Пример Запуска:
import torch.nn.functional as F
from transformers import AutoTokenizer, AutoModel
# Each query needs to be accompanied by an corresponding instruction describing the task.
query_instruction_example = "Given Code or Text, retrieval relevant content"
queries = [
"how to implement quick sort in Python?"
]
# No instruction needed for retrieval passages
passages = [
"def quick_sort(arr):\n if len(arr) <= 1:\n return arr\n pivot = arr[len(arr) // 2]\n left = [x for x in arr if x < pivot]\n middle = [x for x in arr if x == pivot]\n right = [x for x in arr if x > pivot]\n return quick_sort(left) + middle + quick_sort(right)",
"def bubble_sort(arr):\n n = len(arr)\n for i in range(n):\n for j in range(0, n-i-1):\n if arr[j] > arr[j+1]:\n arr[j], arr[j+1] = arr[j+1], arr[j]\n return arr"
]
# load model with tokenizer
model = AutoModel.from_pretrained('Salesforce/SFR-Embedding-Code-2B_R', trust_remote_code=True)
# get the embeddings
max_length = 32768
query_embeddings = model.encode_queries(queries, instruction=query_instruction_example, max_length=max_length)
passage_embeddings = model.encode_corpus(passages, max_length=max_length)
# normalize embeddings
query_embeddings = F.normalize(query_embeddings, p=2, dim=1)
passage_embeddings = F.normalize(passage_embeddings, p=2, dim=1)
scores = (query_embeddings @ passage_embeddings.T) * 100
print(scores.tolist())
✅Документация
✅Модель 400M
✅ Модель 2B
📌Лицензирование моделей: CC-BY-NC-SA-4.0 License.
@ai_machinelearning_big_data
#CodeAI #MLResearch #SOTA #OpenScience #code #llm #ml
BY Machinelearning





Share with your friend now:
group-telegram.com/ai_machinelearning_big_data/6575