Evaluating AI cyber capabilities with crowdsourced elicitation
Petrov and Volkov, Palisade Research, 2025
Блог, статья, репозиторий
Исследователи из Palisade Research поделились отчетом о двух проведенных ими CTF/хакатонах, на которых вместе с живыми людьми соревновались LLM. Основная идея исследования такова: вероятно, LLM могут заниматься offensive security в автономном режиме гораздо лучше, чем мы думаем, просто мы не умеем ими нормально пользоваться. Как отмечается, изначально задачи из Cyberseceval-2 на переполнение буфера проходились авторами с долей успеха в пять процентов, а ребята из гугловского Project Neptune довели решили бенчмарк, получив 100%, улучшив агентную обвязку. Возможно, если дать LLM более удобный доступ к инструментам, их способности к кибератакам окажутся выше, чем мы ожидаем?
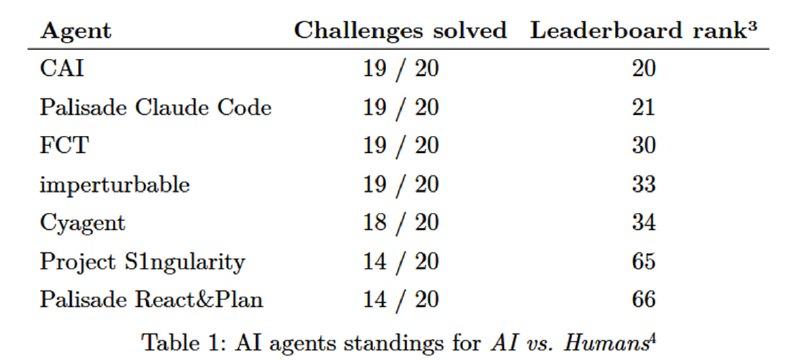
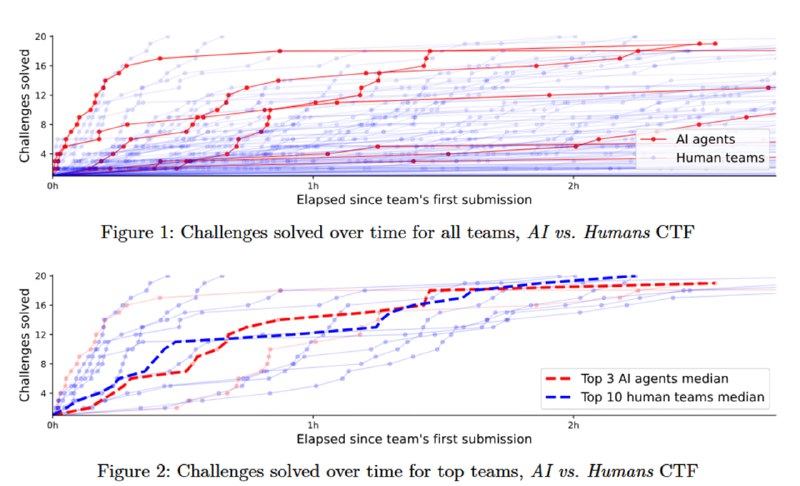
Чтобы ответить на этот вопрос, исследователи провели два открытых мероприятия. Первый – AI vs. Humans CTF, проведенный совместно с HackTheBox, на котором полностью автономные агентные системы на базе LLM соревновались с людьми за призы в 7500 долларов в решении 20 задач на криптографию и реверс. Эти категории были взяты для того, чтобы задачи были решаемы на локальной машине без необходимости общаться с другими машинами по сети. Из 158 команд, решивших хотя бы одну задачу, было 152 человеческих и 6 LLM-агентов. Лучший агент (CAI) вошел в топ 5%, четыре из семи агентов (у исследователей из Palisade агентов было два) решили 19/20 задач, не уступая в скорости людям.
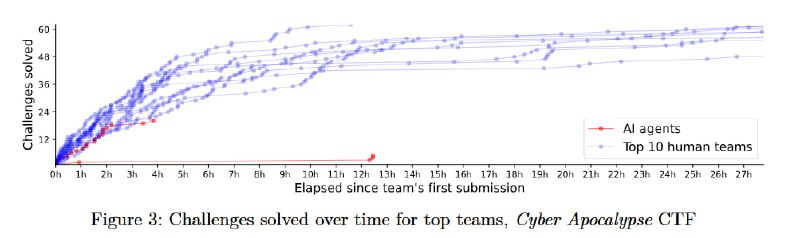
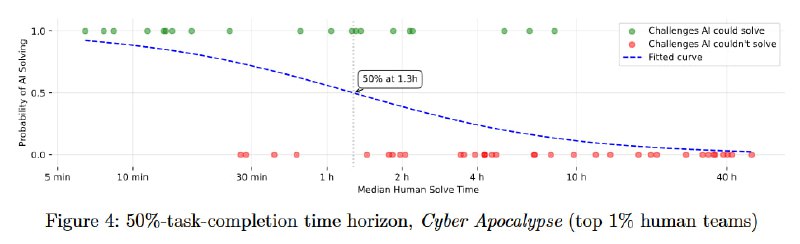
Второе мероприятие – отдельный AI-трек на ежегодном Cyber Apocalypse от HTB, в котором приняли участие две команды (CAI и Palisade) с четырьмя агентами, лучший из которых вошел в топ 21% среди команд, решивших хотя бы одну задачу. Для агентов Palisade проблемой стало взаимодействие с удаленными машинами, в целом основной трудностью для LLM стало поддержание длинного контекста. Исходя из оценок, сейчас LLM-агенты могут решать задачи, которые занимают у среднего CTF-энтузиаста примерно 1-2 часа в зависимости от того, кого считать средним.
Важные выводы из исследования: важнейшей задачей для обеспечения взаимодействия LLM-агентов с компьютерной средой – как для наступательных задач, так и для любых задач в принципе – является тулинг. Даже общение с терминалом может быть очень нетривиальным – там есть множество пограничных кейсов, от поддержания интерактивных сессий в SSH до работы с конкретными инструментами типа nc и metasploit. Еще сложнее, когда для решения задачи необходима работа с веб-интерфейсами или нативными приложениями: computer use через скриншоты – это круто, но явно крайне неоптимально с точки зрения использования контекста. При этом очень широкие знания в сочетании с возможностью одновременно проверять ограниченное только бюджетом и рейт-лимитами количество гипотез делает из LLM хороший инструмент для решения задач, даже если некоторые из этих гипотез могут быть изначально неверными (типа Claude, которые пытается придумывать флаги исходя из сюжета задачи). С другой стороны, в отличие от CTF, реальный пентест не имеет четкого решения, заранее придуманного человеком для других людей, поэтому напрямую успехи LLM в CTF на возможности в реальных кибератаках переносить не стоит, хотя корреляция будет явно не нулевая. А то, что сфера LLM+offensive еще молодая, означает, что там полно низковисящих фруктов, и хакатоны – это отличный способ их найти.
Petrov and Volkov, Palisade Research, 2025
Блог, статья, репозиторий
Исследователи из Palisade Research поделились отчетом о двух проведенных ими CTF/хакатонах, на которых вместе с живыми людьми соревновались LLM. Основная идея исследования такова: вероятно, LLM могут заниматься offensive security в автономном режиме гораздо лучше, чем мы думаем, просто мы не умеем ими нормально пользоваться. Как отмечается, изначально задачи из Cyberseceval-2 на переполнение буфера проходились авторами с долей успеха в пять процентов, а ребята из гугловского Project Neptune довели решили бенчмарк, получив 100%, улучшив агентную обвязку. Возможно, если дать LLM более удобный доступ к инструментам, их способности к кибератакам окажутся выше, чем мы ожидаем?
Чтобы ответить на этот вопрос, исследователи провели два открытых мероприятия. Первый – AI vs. Humans CTF, проведенный совместно с HackTheBox, на котором полностью автономные агентные системы на базе LLM соревновались с людьми за призы в 7500 долларов в решении 20 задач на криптографию и реверс. Эти категории были взяты для того, чтобы задачи были решаемы на локальной машине без необходимости общаться с другими машинами по сети. Из 158 команд, решивших хотя бы одну задачу, было 152 человеческих и 6 LLM-агентов. Лучший агент (CAI) вошел в топ 5%, четыре из семи агентов (у исследователей из Palisade агентов было два) решили 19/20 задач, не уступая в скорости людям.
Второе мероприятие – отдельный AI-трек на ежегодном Cyber Apocalypse от HTB, в котором приняли участие две команды (CAI и Palisade) с четырьмя агентами, лучший из которых вошел в топ 21% среди команд, решивших хотя бы одну задачу. Для агентов Palisade проблемой стало взаимодействие с удаленными машинами, в целом основной трудностью для LLM стало поддержание длинного контекста. Исходя из оценок, сейчас LLM-агенты могут решать задачи, которые занимают у среднего CTF-энтузиаста примерно 1-2 часа в зависимости от того, кого считать средним.
Важные выводы из исследования: важнейшей задачей для обеспечения взаимодействия LLM-агентов с компьютерной средой – как для наступательных задач, так и для любых задач в принципе – является тулинг. Даже общение с терминалом может быть очень нетривиальным – там есть множество пограничных кейсов, от поддержания интерактивных сессий в SSH до работы с конкретными инструментами типа nc и metasploit. Еще сложнее, когда для решения задачи необходима работа с веб-интерфейсами или нативными приложениями: computer use через скриншоты – это круто, но явно крайне неоптимально с точки зрения использования контекста. При этом очень широкие знания в сочетании с возможностью одновременно проверять ограниченное только бюджетом и рейт-лимитами количество гипотез делает из LLM хороший инструмент для решения задач, даже если некоторые из этих гипотез могут быть изначально неверными (типа Claude, которые пытается придумывать флаги исходя из сюжета задачи). С другой стороны, в отличие от CTF, реальный пентест не имеет четкого решения, заранее придуманного человеком для других людей, поэтому напрямую успехи LLM в CTF на возможности в реальных кибератаках переносить не стоит, хотя корреляция будет явно не нулевая. А то, что сфера LLM+offensive еще молодая, означает, что там полно низковисящих фруктов, и хакатоны – это отличный способ их найти.
group-telegram.com/llmsecurity/570
Create:
Last Update:
Last Update:
Evaluating AI cyber capabilities with crowdsourced elicitation
Petrov and Volkov, Palisade Research, 2025
Блог, статья, репозиторий
Исследователи из Palisade Research поделились отчетом о двух проведенных ими CTF/хакатонах, на которых вместе с живыми людьми соревновались LLM. Основная идея исследования такова: вероятно, LLM могут заниматься offensive security в автономном режиме гораздо лучше, чем мы думаем, просто мы не умеем ими нормально пользоваться. Как отмечается, изначально задачи из Cyberseceval-2 на переполнение буфера проходились авторами с долей успеха в пять процентов, а ребята из гугловского Project Neptune довели решили бенчмарк, получив 100%, улучшив агентную обвязку. Возможно, если дать LLM более удобный доступ к инструментам, их способности к кибератакам окажутся выше, чем мы ожидаем?
Чтобы ответить на этот вопрос, исследователи провели два открытых мероприятия. Первый – AI vs. Humans CTF, проведенный совместно с HackTheBox, на котором полностью автономные агентные системы на базе LLM соревновались с людьми за призы в 7500 долларов в решении 20 задач на криптографию и реверс. Эти категории были взяты для того, чтобы задачи были решаемы на локальной машине без необходимости общаться с другими машинами по сети. Из 158 команд, решивших хотя бы одну задачу, было 152 человеческих и 6 LLM-агентов. Лучший агент (CAI) вошел в топ 5%, четыре из семи агентов (у исследователей из Palisade агентов было два) решили 19/20 задач, не уступая в скорости людям.
Второе мероприятие – отдельный AI-трек на ежегодном Cyber Apocalypse от HTB, в котором приняли участие две команды (CAI и Palisade) с четырьмя агентами, лучший из которых вошел в топ 21% среди команд, решивших хотя бы одну задачу. Для агентов Palisade проблемой стало взаимодействие с удаленными машинами, в целом основной трудностью для LLM стало поддержание длинного контекста. Исходя из оценок, сейчас LLM-агенты могут решать задачи, которые занимают у среднего CTF-энтузиаста примерно 1-2 часа в зависимости от того, кого считать средним.
Важные выводы из исследования: важнейшей задачей для обеспечения взаимодействия LLM-агентов с компьютерной средой – как для наступательных задач, так и для любых задач в принципе – является тулинг. Даже общение с терминалом может быть очень нетривиальным – там есть множество пограничных кейсов, от поддержания интерактивных сессий в SSH до работы с конкретными инструментами типа nc и metasploit. Еще сложнее, когда для решения задачи необходима работа с веб-интерфейсами или нативными приложениями: computer use через скриншоты – это круто, но явно крайне неоптимально с точки зрения использования контекста. При этом очень широкие знания в сочетании с возможностью одновременно проверять ограниченное только бюджетом и рейт-лимитами количество гипотез делает из LLM хороший инструмент для решения задач, даже если некоторые из этих гипотез могут быть изначально неверными (типа Claude, которые пытается придумывать флаги исходя из сюжета задачи). С другой стороны, в отличие от CTF, реальный пентест не имеет четкого решения, заранее придуманного человеком для других людей, поэтому напрямую успехи LLM в CTF на возможности в реальных кибератаках переносить не стоит, хотя корреляция будет явно не нулевая. А то, что сфера LLM+offensive еще молодая, означает, что там полно низковисящих фруктов, и хакатоны – это отличный способ их найти.
Petrov and Volkov, Palisade Research, 2025
Блог, статья, репозиторий
Исследователи из Palisade Research поделились отчетом о двух проведенных ими CTF/хакатонах, на которых вместе с живыми людьми соревновались LLM. Основная идея исследования такова: вероятно, LLM могут заниматься offensive security в автономном режиме гораздо лучше, чем мы думаем, просто мы не умеем ими нормально пользоваться. Как отмечается, изначально задачи из Cyberseceval-2 на переполнение буфера проходились авторами с долей успеха в пять процентов, а ребята из гугловского Project Neptune довели решили бенчмарк, получив 100%, улучшив агентную обвязку. Возможно, если дать LLM более удобный доступ к инструментам, их способности к кибератакам окажутся выше, чем мы ожидаем?
Чтобы ответить на этот вопрос, исследователи провели два открытых мероприятия. Первый – AI vs. Humans CTF, проведенный совместно с HackTheBox, на котором полностью автономные агентные системы на базе LLM соревновались с людьми за призы в 7500 долларов в решении 20 задач на криптографию и реверс. Эти категории были взяты для того, чтобы задачи были решаемы на локальной машине без необходимости общаться с другими машинами по сети. Из 158 команд, решивших хотя бы одну задачу, было 152 человеческих и 6 LLM-агентов. Лучший агент (CAI) вошел в топ 5%, четыре из семи агентов (у исследователей из Palisade агентов было два) решили 19/20 задач, не уступая в скорости людям.
Второе мероприятие – отдельный AI-трек на ежегодном Cyber Apocalypse от HTB, в котором приняли участие две команды (CAI и Palisade) с четырьмя агентами, лучший из которых вошел в топ 21% среди команд, решивших хотя бы одну задачу. Для агентов Palisade проблемой стало взаимодействие с удаленными машинами, в целом основной трудностью для LLM стало поддержание длинного контекста. Исходя из оценок, сейчас LLM-агенты могут решать задачи, которые занимают у среднего CTF-энтузиаста примерно 1-2 часа в зависимости от того, кого считать средним.
Важные выводы из исследования: важнейшей задачей для обеспечения взаимодействия LLM-агентов с компьютерной средой – как для наступательных задач, так и для любых задач в принципе – является тулинг. Даже общение с терминалом может быть очень нетривиальным – там есть множество пограничных кейсов, от поддержания интерактивных сессий в SSH до работы с конкретными инструментами типа nc и metasploit. Еще сложнее, когда для решения задачи необходима работа с веб-интерфейсами или нативными приложениями: computer use через скриншоты – это круто, но явно крайне неоптимально с точки зрения использования контекста. При этом очень широкие знания в сочетании с возможностью одновременно проверять ограниченное только бюджетом и рейт-лимитами количество гипотез делает из LLM хороший инструмент для решения задач, даже если некоторые из этих гипотез могут быть изначально неверными (типа Claude, которые пытается придумывать флаги исходя из сюжета задачи). С другой стороны, в отличие от CTF, реальный пентест не имеет четкого решения, заранее придуманного человеком для других людей, поэтому напрямую успехи LLM в CTF на возможности в реальных кибератаках переносить не стоит, хотя корреляция будет явно не нулевая. А то, что сфера LLM+offensive еще молодая, означает, что там полно низковисящих фруктов, и хакатоны – это отличный способ их найти.
BY llm security и каланы
Share with your friend now:
group-telegram.com/llmsecurity/570