When Linear Attention Meets Autoregressive Decoding: Towards More Effective and Efficient Linearized Large Language ModelsДовольно изящный механизм комбинирования ранее известных видов оптимизации скорости вычислений трансформера, которые были известны ранееСейчас я говорю о:
🩰Speculative Sampling (link): идея в распаралелливании авторегрессионой задачи через использовании одной легковестной модели (черновой) и более крупной и "умной" (целевой). В то время, как малютка черновая генерирует некоторое количество токенок, целевая проходится параллельно по выборке и оценивает качество, проверяя, насколько эти токены соответствуют её распределению
🩰Linear Attentions, LAs (link): в attention есть дорогостоящая операция измерения сходства каждого токена с каждым через softmax. Мы можем заменить функцию на более дешевую операцию через ядерное встраивание.
По сути меняем softmax(Q*K^T) на f(Q) * f(K), преобразованные через ядерную функцию, которая “проецирует” их в новое пространство. Таким образом, схожесть между запросами и ключами вычисляется не в исходном пространстве, а в этом новом пространстве признаков.
(я хз как в тг это написать красивее, прошу понять и простить)🩰Grouped Linear Attention: когда мы разделяем входную последовательность на независимые группы токенов. В пределах каждой группы локальные зависимости могут обрабатываться параллельно, что значительно ускоряет вычисления. Уже нечто схожее упоминалось в стаье Grouped-Query Attention
(GQA). Идея разбиения информации для эффективной обработки длинных последовательностей также модифицировано прослеживает в Linformer
(link), Longformer
(link) и LongNet (tg
link)🏃♂️В общем то в первой части исходной статьи авторы замеряют на работает LAs на разных архитектурах (encoder-only, decoder-only, encoder-decoder). Сюрприх-сюрприз: приходят к выводам, что:
💛Linear Attention значительно ускоряет обучение, но показывает себя не настолько эффективно на инференсе авторегрессионной задачи
💛Линейное внимание приводит к
уменьшению latency до 56% и
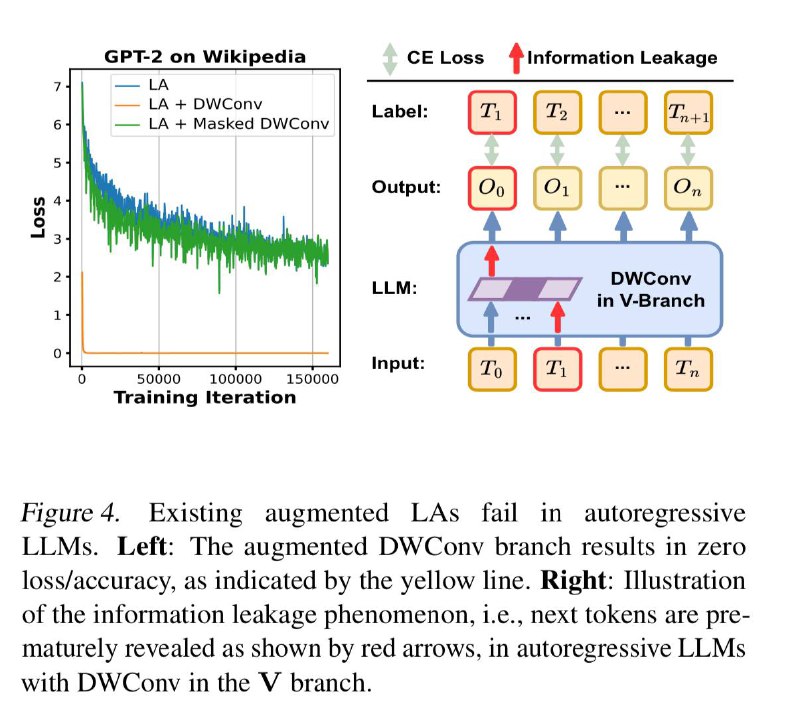
снижению потребления памяти до 37%💛Линейное внимание плохо учитывает последовательные временные зависимости токенов. Это приводит к “утечке информации” (information leakage), когда модель может случайно получить доступ к будущим токенам
👍Эти выводы они использует, как аргумент к комбинации многих из выше описанных подходов и добавления своих механизмов для борьбы с information leakage:
🩰Augmentation: Предлагают маскированную глубинную свёртку
(masked DWConv) как способ улучшить линейное внимание, обеспечив, чтобы каждый токен мог учитывать только предыдущие токены, сохраняя причинно-следственные связи
🩰Используют
Grouped Linear Attention. Для каждой группы вычисляются суммы произведений ключей и значений (KV cumsum), что позволяет минимизировать вычислительные зависимости между группами и повысить эффективность
🩰Как все уже могли догадаться, используют
Speculative Sampling, чтобы повысить эффективность Linear Attention при инференсе
🩰 Unfolded: В Speculative Sampling, для корректной работы с несколькими кандидатами токенов одновременно, они предлагают “разворачивать” свёртки по времени с помощью техники, похожей на img2col, используемую в cv. Это позволяет свёрткам корректно учитывать временные зависимости
📖Статья🖥Код