
Forwarded from rizzearch
FAST: Efficient Action Tokenization for Vision-Language-Action Models
зачем-то physical intelligence, которые делали pi0, себе второй домен забабахали pi.website, на котором запостили как они сделали токенизатор для робо действий
зачем? в принципе трансформер и оперирует в каждом своем слое над дискретными элементами (каждая голова каждого слоя интуитивно проталкивает только определенные токены дальше по сетке), а в роботике часто надо выпуливать многомерные непрерывные действия, так еще часто и с высокой частотой, а если еще пытаться решить достаточно сложную таску, то такую особенность становится невозможно игнорировать
ну и физикал интеллиженс пытался это решить как раз через флоу матчинг в прошлый раз, что более-менее и получилось (с нюансами), но они проработали и альтернативу в виде FAST
при том идея хороша тем, что построена она из привычных рабочих техник
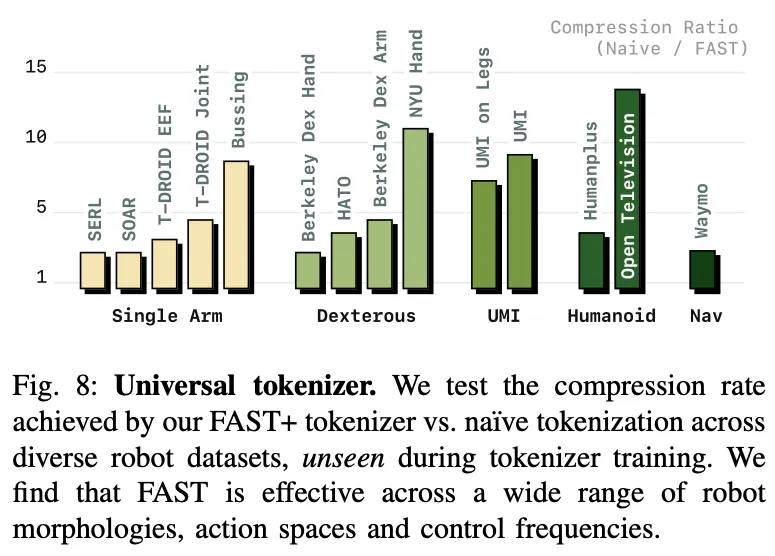
- надо бы как-то эффективно сжимать временные ряды действий. можно бинаризовать - ок, но в случае высокой герцовки робота получается все больше бинов за все меньшее количество времени → медленный инференс. но можно вспомнить (или просто почитать предположение авторов), что траектории действий во времени являются все-таки гладкими, а значит и это можно использовать для компрессии
- lets go to the Discrete Cosine Transform! да, вот такой переход потому что это уже своего рода классика: будем получать наибольшее количество информации в низких частотах, а значит и можно будет сжимать очень многие высокие частоты)
- получим матрицу для каждого action chunk (о важности чего мы упоминали здесь), которую нам неплохо было бы представить в виде последовательности, чтобы потом использовать БПЕ (потому что скорее всего это тоже привычно и довольно удобно) → давайте флаттенить, да при том чтобы низкие частоты были в начале последовательности, а высокие (незначительные) в конце + допом сделаем scale-and-round операцию чтобы округлить до нулей все незначимое
- тогда и можно запускать бпе бррррр
примечательно еще то, что как будто такая идея может и расширяться за пределы обработки действий (а в принципе многомерных временных рядов)
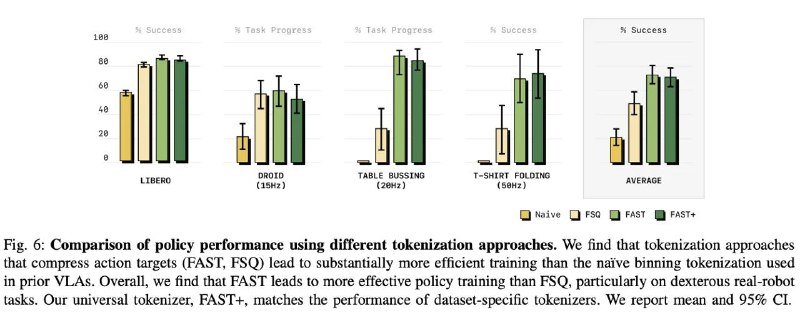
по результатам он даже обгоняет первую версию их pi-модели с флоу матчингом. то есть (имхо) авторы пытаются дать эвиденс о том, что стоит по максимуму токенизировать все что только можно при работе с трансформерами прежде чем приступать к флоу матчингу (даже с трюками авторов по типу бета распределения версия с токенизатором обгоняет по результату, подтвердили на экспах где обучали оба метода до сходимости и где уравнивали бюджет компьюта)
при том это настолько хорошо вкладывается в пайплайн физикал интеллиженса, что они утверждают о возможности зеро-шота на DROID + там где происходит фейл на эпизоде, полиси делает не вообще полностью что-то рандомное
теперь к вопросам, которые появились
- перед DCT происходит нормализация в рейндж от - 1 до 1 на основе статистик датасета по первой и 99 квантили. FAST+, который они выпустили в опенсурс построен аналогичным путем и заявляет о своей универсальности. звучит немного странно с учетом такой нормализации. да, их датасет основан на многих роботах + 1млн траекторий
- но это все равно как будто слишком уникальное дело по поводу токенизации акншнов для робота + так же в экспериментах они говорят об низкой чувствительности к scale параметру перед округлением и вокаб сайзом для БПЕ → выбирают 10 и 1024. как будто второе число довольно-таки мало (особенно сравнивая с вокаб сайзом для лмок что не очень честно но хоть что-то), чтобы с удобоваримым пресижном сжимать действия,
но может я чего-то не понимаю в этой жизни и это довольно-таки интересный инсайт о природе рободействий в нашей реальности
👀 link, демки, code вроде выложили но там нету самой процедуры обучения токенизатора
зачем-то physical intelligence, которые делали pi0, себе второй домен забабахали pi.website, на котором запостили как они сделали токенизатор для робо действий
зачем? в принципе трансформер и оперирует в каждом своем слое над дискретными элементами (каждая голова каждого слоя интуитивно проталкивает только определенные токены дальше по сетке), а в роботике часто надо выпуливать многомерные непрерывные действия, так еще часто и с высокой частотой, а если еще пытаться решить достаточно сложную таску, то такую особенность становится невозможно игнорировать
ну и физикал интеллиженс пытался это решить как раз через флоу матчинг в прошлый раз, что более-менее и получилось (с нюансами), но они проработали и альтернативу в виде FAST
при том идея хороша тем, что построена она из привычных рабочих техник
- надо бы как-то эффективно сжимать временные ряды действий. можно бинаризовать - ок, но в случае высокой герцовки робота получается все больше бинов за все меньшее количество времени → медленный инференс. но можно вспомнить (или просто почитать предположение авторов), что траектории действий во времени являются все-таки гладкими, а значит и это можно использовать для компрессии
- lets go to the Discrete Cosine Transform! да, вот такой переход потому что это уже своего рода классика: будем получать наибольшее количество информации в низких частотах, а значит и можно будет сжимать очень многие высокие частоты)
- получим матрицу для каждого action chunk (о важности чего мы упоминали здесь), которую нам неплохо было бы представить в виде последовательности, чтобы потом использовать БПЕ (потому что скорее всего это тоже привычно и довольно удобно) → давайте флаттенить, да при том чтобы низкие частоты были в начале последовательности, а высокие (незначительные) в конце + допом сделаем scale-and-round операцию чтобы округлить до нулей все незначимое
- тогда и можно запускать бпе бррррр
примечательно еще то, что как будто такая идея может и расширяться за пределы обработки действий (а в принципе многомерных временных рядов)
по результатам он даже обгоняет первую версию их pi-модели с флоу матчингом. то есть (имхо) авторы пытаются дать эвиденс о том, что стоит по максимуму токенизировать все что только можно при работе с трансформерами прежде чем приступать к флоу матчингу (даже с трюками авторов по типу бета распределения версия с токенизатором обгоняет по результату, подтвердили на экспах где обучали оба метода до сходимости и где уравнивали бюджет компьюта)
при том это настолько хорошо вкладывается в пайплайн физикал интеллиженса, что они утверждают о возможности зеро-шота на DROID + там где происходит фейл на эпизоде, полиси делает не вообще полностью что-то рандомное
теперь к вопросам, которые появились
- перед DCT происходит нормализация в рейндж от - 1 до 1 на основе статистик датасета по первой и 99 квантили. FAST+, который они выпустили в опенсурс построен аналогичным путем и заявляет о своей универсальности. звучит немного странно с учетом такой нормализации. да, их датасет основан на многих роботах + 1млн траекторий
- но это все равно как будто слишком уникальное дело по поводу токенизации акншнов для робота + так же в экспериментах они говорят об низкой чувствительности к scale параметру перед округлением и вокаб сайзом для БПЕ → выбирают 10 и 1024. как будто второе число довольно-таки мало (особенно сравнивая с вокаб сайзом для лмок что не очень честно но хоть что-то), чтобы с удобоваримым пресижном сжимать действия,
но может я чего-то не понимаю в этой жизни и это довольно-таки интересный инсайт о природе рободействий в нашей реальности
👀 link, демки, code вроде выложили но там нету самой процедуры обучения токенизатора
group-telegram.com/neural_cell/241
Create:
Last Update:
Last Update:
FAST: Efficient Action Tokenization for Vision-Language-Action Models
зачем-то physical intelligence, которые делали pi0, себе второй домен забабахали pi.website, на котором запостили как они сделали токенизатор для робо действий
зачем? в принципе трансформер и оперирует в каждом своем слое над дискретными элементами (каждая голова каждого слоя интуитивно проталкивает только определенные токены дальше по сетке), а в роботике часто надо выпуливать многомерные непрерывные действия, так еще часто и с высокой частотой, а если еще пытаться решить достаточно сложную таску, то такую особенность становится невозможно игнорировать
ну и физикал интеллиженс пытался это решить как раз через флоу матчинг в прошлый раз, что более-менее и получилось (с нюансами), но они проработали и альтернативу в виде FAST
при том идея хороша тем, что построена она из привычных рабочих техник
- надо бы как-то эффективно сжимать временные ряды действий. можно бинаризовать - ок, но в случае высокой герцовки робота получается все больше бинов за все меньшее количество времени → медленный инференс. но можно вспомнить (или просто почитать предположение авторов), что траектории действий во времени являются все-таки гладкими, а значит и это можно использовать для компрессии
- lets go to the Discrete Cosine Transform! да, вот такой переход потому что это уже своего рода классика: будем получать наибольшее количество информации в низких частотах, а значит и можно будет сжимать очень многие высокие частоты)
- получим матрицу для каждого action chunk (о важности чего мы упоминали здесь), которую нам неплохо было бы представить в виде последовательности, чтобы потом использовать БПЕ (потому что скорее всего это тоже привычно и довольно удобно) → давайте флаттенить, да при том чтобы низкие частоты были в начале последовательности, а высокие (незначительные) в конце + допом сделаем scale-and-round операцию чтобы округлить до нулей все незначимое
- тогда и можно запускать бпе бррррр
примечательно еще то, что как будто такая идея может и расширяться за пределы обработки действий (а в принципе многомерных временных рядов)
по результатам он даже обгоняет первую версию их pi-модели с флоу матчингом. то есть (имхо) авторы пытаются дать эвиденс о том, что стоит по максимуму токенизировать все что только можно при работе с трансформерами прежде чем приступать к флоу матчингу (даже с трюками авторов по типу бета распределения версия с токенизатором обгоняет по результату, подтвердили на экспах где обучали оба метода до сходимости и где уравнивали бюджет компьюта)
при том это настолько хорошо вкладывается в пайплайн физикал интеллиженса, что они утверждают о возможности зеро-шота на DROID + там где происходит фейл на эпизоде, полиси делает не вообще полностью что-то рандомное
теперь к вопросам, которые появились
- перед DCT происходит нормализация в рейндж от - 1 до 1 на основе статистик датасета по первой и 99 квантили. FAST+, который они выпустили в опенсурс построен аналогичным путем и заявляет о своей универсальности. звучит немного странно с учетом такой нормализации. да, их датасет основан на многих роботах + 1млн траекторий
- но это все равно как будто слишком уникальное дело по поводу токенизации акншнов для робота + так же в экспериментах они говорят об низкой чувствительности к scale параметру перед округлением и вокаб сайзом для БПЕ → выбирают 10 и 1024. как будто второе число довольно-таки мало (особенно сравнивая с вокаб сайзом для лмок что не очень честно но хоть что-то), чтобы с удобоваримым пресижном сжимать действия,
но может я чего-то не понимаю в этой жизни и это довольно-таки интересный инсайт о природе рободействий в нашей реальности
👀 link, демки, code вроде выложили но там нету самой процедуры обучения токенизатора
зачем-то physical intelligence, которые делали pi0, себе второй домен забабахали pi.website, на котором запостили как они сделали токенизатор для робо действий
зачем? в принципе трансформер и оперирует в каждом своем слое над дискретными элементами (каждая голова каждого слоя интуитивно проталкивает только определенные токены дальше по сетке), а в роботике часто надо выпуливать многомерные непрерывные действия, так еще часто и с высокой частотой, а если еще пытаться решить достаточно сложную таску, то такую особенность становится невозможно игнорировать
ну и физикал интеллиженс пытался это решить как раз через флоу матчинг в прошлый раз, что более-менее и получилось (с нюансами), но они проработали и альтернативу в виде FAST
при том идея хороша тем, что построена она из привычных рабочих техник
- надо бы как-то эффективно сжимать временные ряды действий. можно бинаризовать - ок, но в случае высокой герцовки робота получается все больше бинов за все меньшее количество времени → медленный инференс. но можно вспомнить (или просто почитать предположение авторов), что траектории действий во времени являются все-таки гладкими, а значит и это можно использовать для компрессии
- lets go to the Discrete Cosine Transform! да, вот такой переход потому что это уже своего рода классика: будем получать наибольшее количество информации в низких частотах, а значит и можно будет сжимать очень многие высокие частоты)
- получим матрицу для каждого action chunk (о важности чего мы упоминали здесь), которую нам неплохо было бы представить в виде последовательности, чтобы потом использовать БПЕ (потому что скорее всего это тоже привычно и довольно удобно) → давайте флаттенить, да при том чтобы низкие частоты были в начале последовательности, а высокие (незначительные) в конце + допом сделаем scale-and-round операцию чтобы округлить до нулей все незначимое
- тогда и можно запускать бпе бррррр
примечательно еще то, что как будто такая идея может и расширяться за пределы обработки действий (а в принципе многомерных временных рядов)
по результатам он даже обгоняет первую версию их pi-модели с флоу матчингом. то есть (имхо) авторы пытаются дать эвиденс о том, что стоит по максимуму токенизировать все что только можно при работе с трансформерами прежде чем приступать к флоу матчингу (даже с трюками авторов по типу бета распределения версия с токенизатором обгоняет по результату, подтвердили на экспах где обучали оба метода до сходимости и где уравнивали бюджет компьюта)
при том это настолько хорошо вкладывается в пайплайн физикал интеллиженса, что они утверждают о возможности зеро-шота на DROID + там где происходит фейл на эпизоде, полиси делает не вообще полностью что-то рандомное
теперь к вопросам, которые появились
- перед DCT происходит нормализация в рейндж от - 1 до 1 на основе статистик датасета по первой и 99 квантили. FAST+, который они выпустили в опенсурс построен аналогичным путем и заявляет о своей универсальности. звучит немного странно с учетом такой нормализации. да, их датасет основан на многих роботах + 1млн траекторий
- но это все равно как будто слишком уникальное дело по поводу токенизации акншнов для робота + так же в экспериментах они говорят об низкой чувствительности к scale параметру перед округлением и вокаб сайзом для БПЕ → выбирают 10 и 1024. как будто второе число довольно-таки мало (особенно сравнивая с вокаб сайзом для лмок что не очень честно но хоть что-то), чтобы с удобоваримым пресижном сжимать действия,
но может я чего-то не понимаю в этой жизни и это довольно-таки интересный инсайт о природе рободействий в нашей реальности
👀 link, демки, code вроде выложили но там нету самой процедуры обучения токенизатора
BY the last neural cell




Share with your friend now:
group-telegram.com/neural_cell/241