🤖 Почему модели лучше отвечают на вопросы по тексту, чем по изображениям — и как это исправить?
Vision-Language модели (VLMs) сильно хуже справляются с вопросами про картинки (*«Сколько книг на изображении?»*), чем с теми же вопросами по тексту (*«Сколько книг в описании?»*). И нашли способ улучшить результат на +4.6%, закрыв треть разрыва между модальностями! Вот что они сделали 👇
🔬 Они разделили вход на три части: • Данные (изображение или текст), • Вопрос (*how many…*), • Ответ (предсказание последнего слова).
🧠 Что нашли:
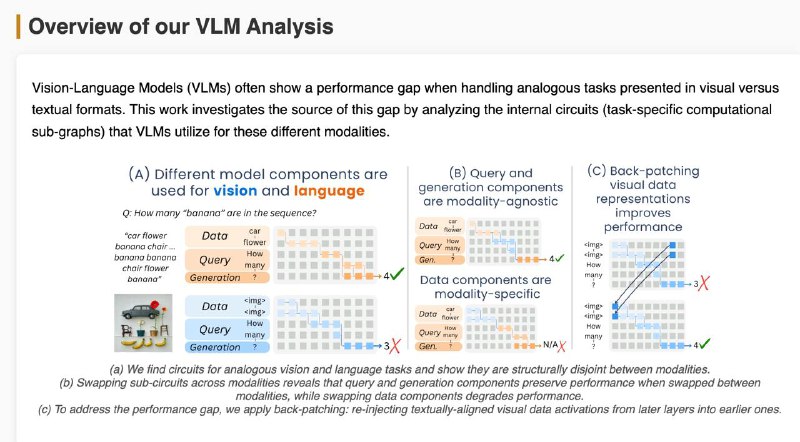
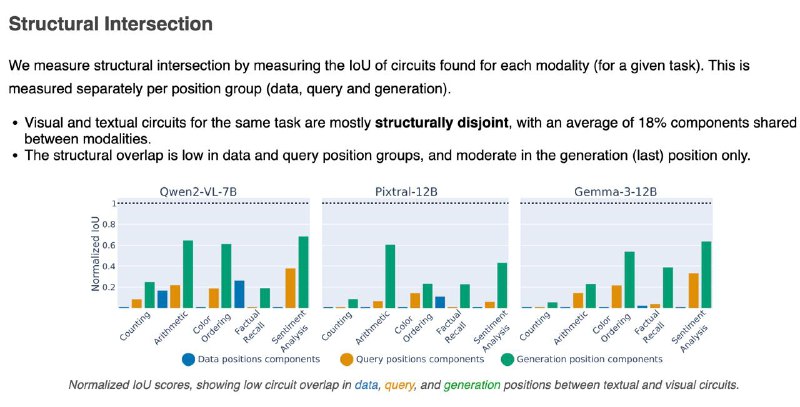
1️⃣Мозги у модели разные для текста и картинок — цепочки внимания и нейроны почти не совпадают (всего ~18%). Особенно в частях, где обрабатываются данные и вопрос.
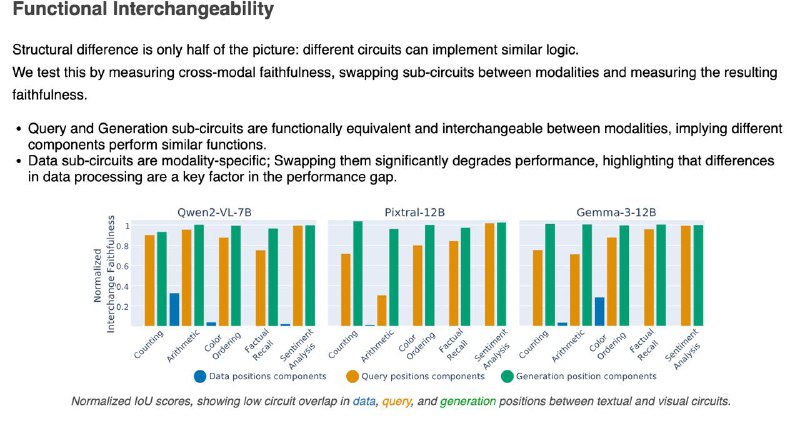
2️⃣Часть, отвечающая за генерацию ответа, похожа — можно даже подменить её между модальностями, и модель почти не теряет в точности.
3️⃣Часть, которая "смотрит" на данные — строго модальная. Визуальный поток информации идёт по другому пути, и замена разрушает результат.
4️⃣Проблема в том, что изображение “становится понятным” слишком поздно. В поздних слоях визуальные данные уже похожи на текстовые — но модель не успевает этим воспользоваться.
💡 Решение: "перемотать" визуальные данные из поздних слоёв обратно в ранние (back-patching) — это помогает модели раньше "понять" картинку.
📈 Результат: +4.6% точности при ответах на вопросы по изображению — и треть разрыва с текстом закрыта!
🧩 Вывод: архитектура не виновата. Просто визуальные данные нужно правильно "подать" — и VLM начинает думать почти как человек.
🤖 Почему модели лучше отвечают на вопросы по тексту, чем по изображениям — и как это исправить?
Vision-Language модели (VLMs) сильно хуже справляются с вопросами про картинки (*«Сколько книг на изображении?»*), чем с теми же вопросами по тексту (*«Сколько книг в описании?»*). И нашли способ улучшить результат на +4.6%, закрыв треть разрыва между модальностями! Вот что они сделали 👇
🔬 Они разделили вход на три части: • Данные (изображение или текст), • Вопрос (*how many…*), • Ответ (предсказание последнего слова).
🧠 Что нашли:
1️⃣Мозги у модели разные для текста и картинок — цепочки внимания и нейроны почти не совпадают (всего ~18%). Особенно в частях, где обрабатываются данные и вопрос.
2️⃣Часть, отвечающая за генерацию ответа, похожа — можно даже подменить её между модальностями, и модель почти не теряет в точности.
3️⃣Часть, которая "смотрит" на данные — строго модальная. Визуальный поток информации идёт по другому пути, и замена разрушает результат.
4️⃣Проблема в том, что изображение “становится понятным” слишком поздно. В поздних слоях визуальные данные уже похожи на текстовые — но модель не успевает этим воспользоваться.
💡 Решение: "перемотать" визуальные данные из поздних слоёв обратно в ранние (back-patching) — это помогает модели раньше "понять" картинку.
📈 Результат: +4.6% точности при ответах на вопросы по изображению — и треть разрыва с текстом закрыта!
🧩 Вывод: архитектура не виновата. Просто визуальные данные нужно правильно "подать" — и VLM начинает думать почти как человек.
Recently, Durav wrote on his Telegram channel that users' right to privacy, in light of the war in Ukraine, is "sacred, now more than ever." The news also helped traders look past another report showing decades-high inflation and shake off some of the volatility from recent sessions. The Bureau of Labor Statistics' February Consumer Price Index (CPI) this week showed another surge in prices even before Russia escalated its attacks in Ukraine. The headline CPI — soaring 7.9% over last year — underscored the sticky inflationary pressures reverberating across the U.S. economy, with everything from groceries to rents and airline fares getting more expensive for everyday consumers. Since its launch in 2013, Telegram has grown from a simple messaging app to a broadcast network. Its user base isn’t as vast as WhatsApp’s, and its broadcast platform is a fraction the size of Twitter, but it’s nonetheless showing its use. While Telegram has been embroiled in controversy for much of its life, it has become a vital source of communication during the invasion of Ukraine. But, if all of this is new to you, let us explain, dear friends, what on Earth a Telegram is meant to be, and why you should, or should not, need to care. "For Telegram, accountability has always been a problem, which is why it was so popular even before the full-scale war with far-right extremists and terrorists from all over the world," she told AFP from her safe house outside the Ukrainian capital. Telegram, which does little policing of its content, has also became a hub for Russian propaganda and misinformation. Many pro-Kremlin channels have become popular, alongside accounts of journalists and other independent observers.
from de