🤖 Почему модели лучше отвечают на вопросы по тексту, чем по изображениям — и как это исправить?
Vision-Language модели (VLMs) сильно хуже справляются с вопросами про картинки (*«Сколько книг на изображении?»*), чем с теми же вопросами по тексту (*«Сколько книг в описании?»*). И нашли способ улучшить результат на +4.6%, закрыв треть разрыва между модальностями! Вот что они сделали 👇
🔬 Они разделили вход на три части: • Данные (изображение или текст), • Вопрос (*how many…*), • Ответ (предсказание последнего слова).
🧠 Что нашли:
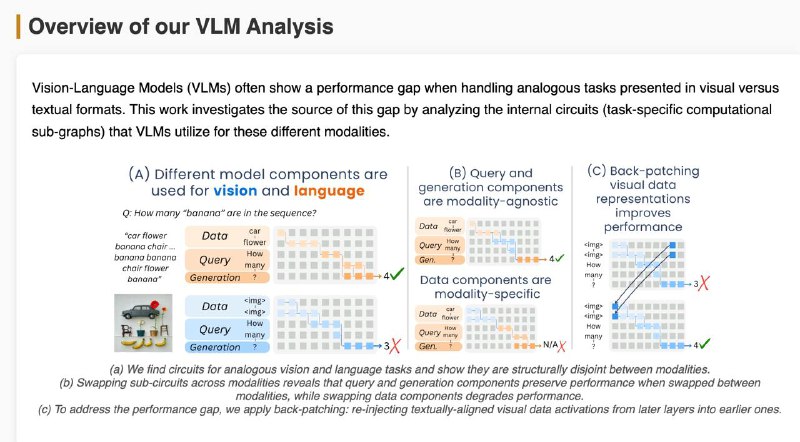
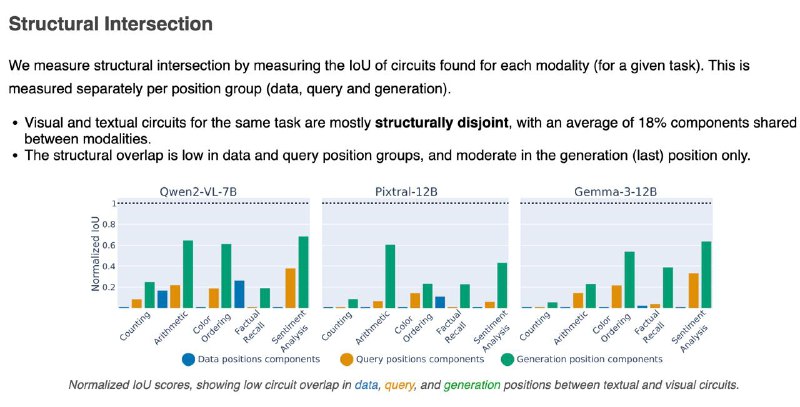
1️⃣Мозги у модели разные для текста и картинок — цепочки внимания и нейроны почти не совпадают (всего ~18%). Особенно в частях, где обрабатываются данные и вопрос.
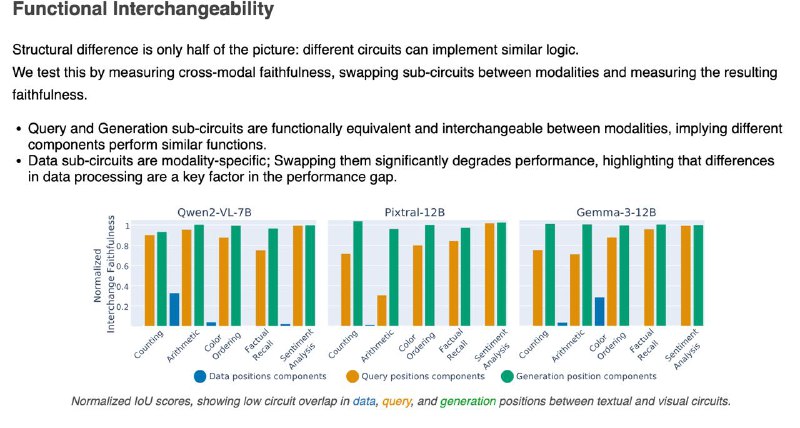
2️⃣Часть, отвечающая за генерацию ответа, похожа — можно даже подменить её между модальностями, и модель почти не теряет в точности.
3️⃣Часть, которая "смотрит" на данные — строго модальная. Визуальный поток информации идёт по другому пути, и замена разрушает результат.
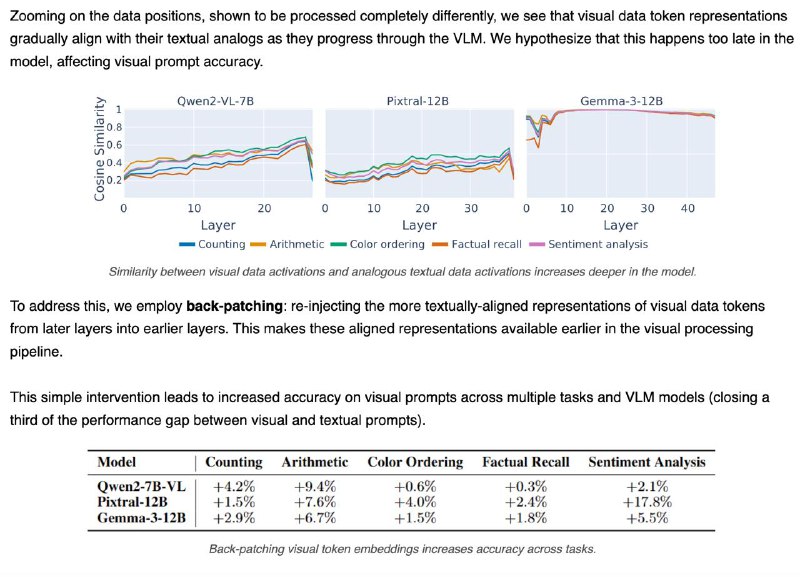
4️⃣Проблема в том, что изображение “становится понятным” слишком поздно. В поздних слоях визуальные данные уже похожи на текстовые — но модель не успевает этим воспользоваться.
💡 Решение: "перемотать" визуальные данные из поздних слоёв обратно в ранние (back-patching) — это помогает модели раньше "понять" картинку.
📈 Результат: +4.6% точности при ответах на вопросы по изображению — и треть разрыва с текстом закрыта!
🧩 Вывод: архитектура не виновата. Просто визуальные данные нужно правильно "подать" — и VLM начинает думать почти как человек.
🤖 Почему модели лучше отвечают на вопросы по тексту, чем по изображениям — и как это исправить?
Vision-Language модели (VLMs) сильно хуже справляются с вопросами про картинки (*«Сколько книг на изображении?»*), чем с теми же вопросами по тексту (*«Сколько книг в описании?»*). И нашли способ улучшить результат на +4.6%, закрыв треть разрыва между модальностями! Вот что они сделали 👇
🔬 Они разделили вход на три части: • Данные (изображение или текст), • Вопрос (*how many…*), • Ответ (предсказание последнего слова).
🧠 Что нашли:
1️⃣Мозги у модели разные для текста и картинок — цепочки внимания и нейроны почти не совпадают (всего ~18%). Особенно в частях, где обрабатываются данные и вопрос.
2️⃣Часть, отвечающая за генерацию ответа, похожа — можно даже подменить её между модальностями, и модель почти не теряет в точности.
3️⃣Часть, которая "смотрит" на данные — строго модальная. Визуальный поток информации идёт по другому пути, и замена разрушает результат.
4️⃣Проблема в том, что изображение “становится понятным” слишком поздно. В поздних слоях визуальные данные уже похожи на текстовые — но модель не успевает этим воспользоваться.
💡 Решение: "перемотать" визуальные данные из поздних слоёв обратно в ранние (back-patching) — это помогает модели раньше "понять" картинку.
📈 Результат: +4.6% точности при ответах на вопросы по изображению — и треть разрыва с текстом закрыта!
🧩 Вывод: архитектура не виновата. Просто визуальные данные нужно правильно "подать" — и VLM начинает думать почти как человек.
A Russian Telegram channel with over 700,000 followers is spreading disinformation about Russia's invasion of Ukraine under the guise of providing "objective information" and fact-checking fake news. Its influence extends beyond the platform, with major Russian publications, government officials, and journalists citing the page's posts. "We're seeing really dramatic moves, and it's all really tied to Ukraine right now, and in a secondary way, in terms of interest rates," Octavio Marenzi, CEO of Opimas, told Yahoo Finance Live on Thursday. "This war in Ukraine is going to give the Fed the ammunition, the cover that it needs, to not raise interest rates too quickly. And I think Jay Powell is a very tepid sort of inflation fighter and he's not going to do as much as he needs to do to get that under control. And this seems like an excuse to kick the can further down the road still and not do too much too soon." As a result, the pandemic saw many newcomers to Telegram, including prominent anti-vaccine activists who used the app's hands-off approach to share false information on shots, a study from the Institute for Strategic Dialogue shows. On Telegram’s website, it says that Pavel Durov “supports Telegram financially and ideologically while Nikolai (Duvov)’s input is technological.” Currently, the Telegram team is based in Dubai, having moved around from Berlin, London and Singapore after departing Russia. Meanwhile, the company which owns Telegram is registered in the British Virgin Islands. If you initiate a Secret Chat, however, then these communications are end-to-end encrypted and are tied to the device you are using. That means it’s less convenient to access them across multiple platforms, but you are at far less risk of snooping. Back in the day, Secret Chats received some praise from the EFF, but the fact that its standard system isn’t as secure earned it some criticism. If you’re looking for something that is considered more reliable by privacy advocates, then Signal is the EFF’s preferred platform, although that too is not without some caveats.
from in

{kind=link}